What is data labeling?
Data labeling is the process of assigning descriptions to unstructured information like pictures, videos, texts, audio files, and 3D point clouds. A machine learning model can be trained to recognize instances of a given class of objects when they appear in data for which no tags have been provided by adding these labels as a representation of the class to which the data belongs. This information has been gathered specifically to feed it to a machine learning model for training algorithms.
Forms of Typically Labeled Data
Based on what we have seen so far, data labeling is all about the specific task we wish to assign to a machine-learning system. Images of rust or cracks are fed into a machine learning system trained for defect inspection. A crack or corrosion area might be annotated with a polygon, and the area itself could be annotated with a tag.
Types of data annotation used in some of the most popular AI fields are listed below.
Classification of images
Annotating data for image classification requires adding a label to the image for later reference. The number of categories that can be assigned by the model is equal to the total number of distinct tags in the data set.
Images are machine-readable after being labeled with various techniques such as 2D bounding box extraction, polygon annotation, semantic segmentation, and many more.
Textual annotation
Data annotators add specific metadata to selected words or phrases to train ML algorithms on the meaning and context of each word or phrase. Sentiment analysis, in which people assign emotional states like “angry” or “glad” to text, is a typical use. To ensure that user contributions on platforms like Facebook and other forums adhere to the site’s guidelines, moderators utilize text labeling.
Segmenting Images
In Picture Segmentation, a Computer Vision algorithm is tasked with identifying and removing unwanted elements from an image, such as the backdrop or other objects. This usually takes the form of a pixel map of the same size as the image, with 1s representing the presence of the object and 0s representing the absence of an annotation.
To segment numerous objects from the same image, the pixel mappings corresponding to each object are combined channel-by-channel and then utilized as training data for the model.
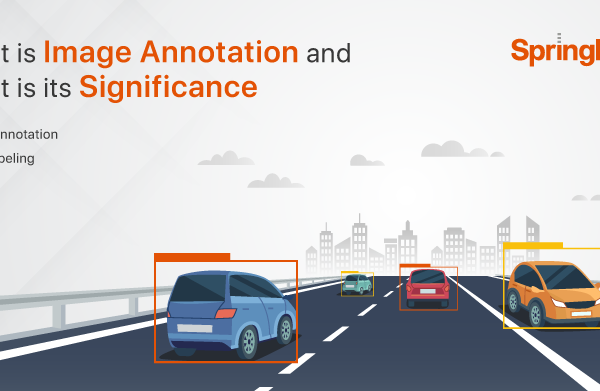
Detecting Objects
Object detection is the process of using computer vision to identify and localize physical things.
When it comes to data annotation, object detection differs greatly from Image Classification since each item is marked with bounding boxes. When describing an object in an image, the term “bounding box” refers to the smallest rectangular region that adequately encompasses the subject. In most cases, labels are added to the image alongside bounding box annotations.
Labeling a 3D point cloud
LiDARs generate 3D Point clouds, which are a visual depiction of how an AI system perceives the physical world. In the process of creating autonomous vehicles, 3D Point Clouds are frequently used to teach machine learning (ML) algorithms to recognize every surface present on the route.
Labeling audio files
Audio sources such as humans, animals, the natural world, musical instruments, and so on must be categorized. Audio labeling is essential for artificial intelligence applications that need to distinguish between different types of sounds, such as those made by endangered animals so that their movements and population sizes may be tracked.
Labeling video
Video labeling is the process of tagging video datasets with information. Details on people, places, things, and other entities can fall under this category. Labeling is used to teach machine learning algorithms to identify inappropriate user-generated content on websites like YouTube.
Process of Data Labeling
Procedures for assigning labels to data go as follows:
Collection of the data:
The process of gathering the raw data needed to train the model begins. To feed this information into the model, it is first cleaned and processed.
Information tagging
The data is labeled using a variety of methods, giving it meaningful tags and associations that the machine may use as a reference point.
Quality inspection
The accuracy of the coordinate points used in bounding box and keypoint annotations, as well as the precision of the tags assigned to individual data points, are major factors in determining the quality of annotated data. For an overall sense of how reliable these annotations are, QA algorithms like the Consensus algorithm and Cronbach’s alpha test can be quite instructive.
Conclusion
With the wide variety of annotation and tagging capabilities made available at Springbord, annotation of data for purposes such as segmentation, classification, object identification, and posture estimation can be done quickly and accurately. Additionally, Springbord enables you to train your models on the web, making the entire procedure of creating an AI model quick and simple.